

This is the story of how and why Google switched to numeric captchas. Captchas are these wiggly words used as a puzzle to tell humans apart from computers. Over the last few years, based on my work that began at Stanford, Ive been working on designing a more user-friendly captcha for Google that started to be used in October 2013 in the signup page. Overall, this new captcha has been a success: people are 6.7% more accurate at solving it compared to the old one. Deploying this captcha also helped to reduce frustration: people click 55% less on the reload button for the new captcha. The following screenshots show the difference between the previous captcha and our new user-friendly one:
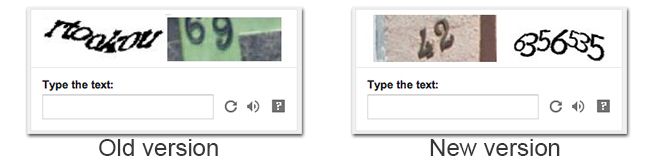
It should be obvious that this new captcha is easier to break for a computer than the old one. Thats why we only show it when our risk analysis system already has a high confidence that the user is human. Developing this captcha scheme was a bumpy road as we had to overcome several unexpected difficulties that are summarized in the research paper that we will present at CHI this year. In particular, we came across a very intriguing effect: The meaning of the word used in the captcha deeply influences both how people perceive its difficulty and how pleasant the task of answering it to be. This effect ultimately influenced our decision to ditch letters and replace them with numbers. While this effect is the subject of this blog post, before delving into it, let me tell you a little about our design process so its easier to understand how and when this effect surfaced and why it forced us to rethink our approach. To design the best captcha possible, we tested ten of thousands of designs by varying a slew of features including the font size, the type of security features used, and the color used and measuring of successful people were at solving them. A visual illustration of some of the features we tested are depicted in the screenshot below:

We evaluated how usable those various captcha schemes were by measuring how fast and accurate people were at solving them. One of the most important decision was which character set to use. To answer this questions we evaluated captcha using random strings using different character sets and using words. The result of this particular test is summarized in the table below. To keep measures meaningful, we kept the length of the captcha fixed at six characters during this experiment.
| Charset | Solving time | Accuracy |
|---|---|---|
| Word | 4.3s | 98% |
| Pseudo-word | 5.0s | 99% |
| 0-9 | 6.1s | 98% |
| a-z | 6.6s | 97% |
| a-zA-Z0-9 | 8.3 | 82% |
Given that each captcha used in this measurement was six letters long, I was puzzled at first by the fact that humans appear to be faster at processing words than random strings. However, after discussing this with Dan Jurafsky (a professor of linguistics and computer science at Stanford whos a co-author of the research), it became clear: the cognitive process involved in recognizing words is drastically different than the one involved in processing random strings. People recognize a word as a whole, whereas they process meaningless strings one character at a time. A way to experience this is to simply try to read the following paragraph:
“it deosnt mttaer in waht oredr the ltteers in a wrod are, the olny iprmoetnt tihng is taht the frist and lsat ltteer be at the rghit pclae. The rset can be a toatl mses and you can sitll raed it wouthit porbelm. Tihs is bcuseae the huamn mnid deos not raed ervey lteter by istlef, but the wrod as a wlohe.”
While the origin of this experiment is hard to trace, it is by far the most-known experiment about the brain recognizing words as units rather than reading them letter by letter. Based on our measurements, one might conclude that words and pseudo-words should be the best choice for a captcha. After all, people are faster and more accurate at solving them, right? So why did we switch to digits? The answer lies in how people perceive the difficulty of solving word and pseudo-word captchas: it varies dramatically depending on which word is used in the captcha. Pseudo-words being the worst and consistently perceived as the most difficult. This perceptual difficulty is best captured by running surveys asking people which captcha is easier, which is faster, and which one they would prefer to solve. For example, the figure below summarizes the result of a survey I ran on 5,000 people using Google Consumer Surveys to measure this perceptual difficulty.
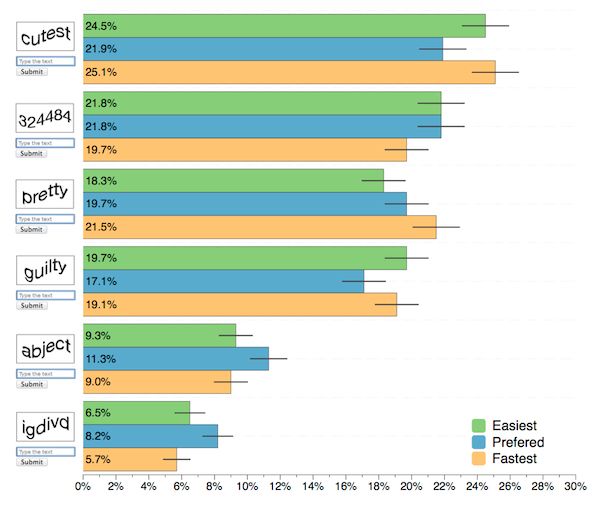
As visible in the chart, people clearly favor certain words (and digits!) over others even though they take exactly the same amount of time to solve and accuracy because they have the same length. This experiment clearly demonstrates that relying on accuracy and solving time measurements was not enough to evaluate how people perceive captcha difficulty. Over a cup of coffee, I asked Dan what he thought might be the extra factor or factors that influences peoples perception of captcha difficulty. He almost immediately offered what became our main hypothesis: People are unconsciously biased by the meaning and the frequency of the words used in the captcha. For example, for our survey we chose the word pretty as an example of a high frequency positive word, and cutest as a low frequency positive word. Google search returned approximately 1.1 billion results for pretty and about 36 million results for cutest. We chose guilty as a high frequency negative word, and abject as a low frequency negative word. These words had 150 million and 4 million Google search results, respectively. As you can see above, the survey results match our hypothesis perfectly: users have a clear preference for positive words over negative words. The survey also confirms that low frequency words negatively impact user perception. So what about pseudo-words? Our hypothesis is that they create a dissonance in the brain because we try to recognize them, and we fail. Thats an unpleasant feeling. Here you have it: an unconscious semantic bias introduced by words led us to reject using words in our captcha schemes. This bias makes it impossible to generate hundreds of millions of captchas with consistent user sentiment. Im still actively researching how this unconscious bias affects other area, including design mocks. Read our research paper to learn more on how we designed our new captcha and don’t forget to share this post if you like it!


